I don't know of a standard method, but it shouldn't be too difficult to make some metric of the variation in an orthographic form.
We'll use the Wright-Fisher model, which is used to model genetic drift in biology.
Let's say that a word has orthographic variants x and y, and their prevalences at time t = 0 are px(0) and py(0) = 1 – px(t). Imagine that all of the tokens of our word belong in generation 0. Now we start to do a procedure like this:
- Select N words at random from generation 0, using the prevalences at t = 0
- Now the words that we have selected form generation 1, which has its own prevalences, px(1) and 1 – px(1).
- Select N words from generation 1 to create generation 2, and so on, until we get to generation n where either px(n) = 0 or px(n) = 1. At this point we can say that one variant of the word has fixed, and there is no more drift.
A way of measuring how much longer the system is going to drift is by calculating the mean fixation time, or the average number of generations from generation 0 that it takes for one variant to fix. For large N, this number is:
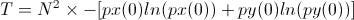
Since we set N arbitrarily, the important term is the one with the logarithms in it, which is equivalent to the entropy of the system, though the choice of base is e rather than 2. So if I were starting from scratch, I'd take the entropy as a way of quantifying the present variability, and the amount of time remaining before the system stabilizes, as a baseline measure.
Just a thought.
Principles of Evolution eds. H Meyer-Ortmanns and S. Thurner (Springer, 2011).